Learning Objectives
- Review identity search, substructure/superstructure search, and similarity search.
- Review basic knowledge of molecular similarity methods.
- Learn how to retrieve bioactivity data from PubChem.
- Learn how to use PubChem’s Structure Clustering and Structure-Activity Relationship (SAR) Analysis tools.
- Learn how to analyze bioactivity data using PubChem’s web-based interfaces.
1. Searching PubChem using a non-textual query
This section describes various searches that can be performed in PubChem.1-3 Currently PubChem has three different search interfaces:
- PubChem homepage (http://pubchem.ncbi.nlm.nih.gov)
- PubChem Chemical Structure Search (https://pubchem.ncbi.nlm.nih.gov/search/search.cgi)
- PubChem Search (https://pubchem.ncbi.nlm.nih.gov/search/).
As explained in Module 5, the PubChem homepage provides a search interface for all three primary databases (e.g., Substance, Compound, and BioAssay). However, the search box on the PubChem homepage can accepts textual keywords only, and it is difficult to input non-textual queries (such as chemical structures). The PubChem Chemical Structure Search allows users to perform various searches using both textual and non-textual queries. This search interface is integrated with PubChem Sketcher,4 which enables users to provide the 2-D structure of a molecule as a query for chemical structure search. While the PubChem Chemical Structure Search is limited to search for chemical structures, the PubChem Search allows users to search for bioassays, bioactivities, patents, and targets as well as chemical structures, but it is still in beta testing. In this module, we use the Chemical Structure Search for chemical structure search.
1.1. Molecular formula search
Molecular formula search allows one to find molecules that contain a certain number and type of elements. Typically, molecular formula search returns by default molecules that exactly match the queried stoichiometry. For example, a query of “C6H6” will return all structures containing six carbon atoms, six hydrogen atoms and nothing else. However, molecular formula search implemented in some databases, including PubChem Chemical Structure Search, has an option to allow other elements in returned hits (e.g., C6H6O or C6H6N2O for the “C6H6” query).
1.2. Identity search
Identity search is to locate a particular chemical structure that is “identical” to the query chemical structure. Although identity search seems conceptually straightforward, one should keep in mind that the word “identical” can have different notions. For example, if a molecule exists as multiple tautomeric forms in equilibrium, do you want to consider all these tautomers identical and search the database for all of them? If your query molecule has a chiral stereo center, should you consider both R- and S-forms in your search? In your identity search, do you want to include isotopically substituted species of the provided query molecule as well as the query itself? Depending on how to deal with these nuances of chemical structures, identical search will return different results. The identity search in the PubChem Chemical Structure Search allows users to choose a desired degree of “sameness” from several predefined options. To see these options, one need to expand the options section by clicking the “plus” button next to the “option” section heading.
1.3. Substructure and superstructure search
When a chemical structure occurs as a part of a bigger chemical structure, the former is called a substructure and the latter is referred to as a superstructure. For example, ethanol is a substructure of acetic acid, and acetic acid is a superstructure of ethanol.
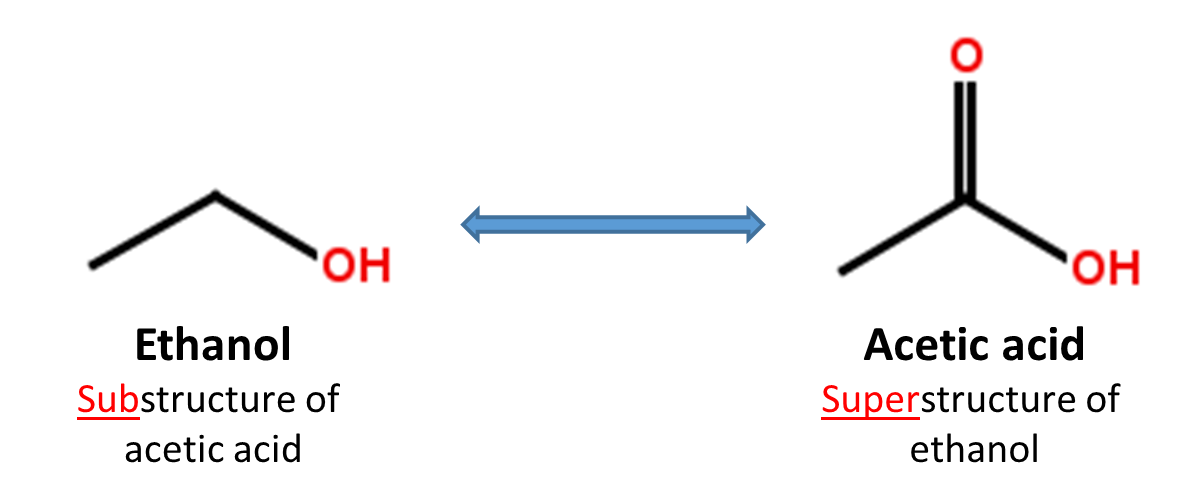
In substructure search, one provides an input substructure as a query to find molecules that contain the query substructure (that is, superstructures that contain the query substructure). On the contrary, superstructure search returns molecules that comprise or make up the provided chemical structure query (that is, substructures that is contained in the query superstructure). It should be noted that substructure search does not give you substructures of the query and that superstructure search does not return superstructures of the query.
It is possible to include explicit hydrogen atoms as part of the pattern being searched. For example, if you choose to do so, the SMILES queries [CH2][CH2][OH] and [CH3][CH][OH] will return molecules whose formula are R-CH2-CH2-OH and CH3-CH(R)-OH, respectively. Substructure/superstructure searches implemented in some databases remove by default explicit hydrogens from the query molecule prior to search, the two SMILES queries [CH2][CH2][OH] and [CH3][CH][OH] may give you the same result as what the SMILES query CCO does, unless you specify that explicit hydrogens should be included in pattern matching.
In addition to explicit hydrogen atoms, there are additional factors that may affect results of substructure/superstructure searches, for example, whether to ignore stereochemistry, isotopism, tautomerism, formal charge, and so on.
1.4. Similarity search
Molecular similarity (also called chemical similarity or chemical structure similarity) is a fundamental concept in cheminformatics, playing an important role in computational methods for predicting properties of chemical compounds as well as designing chemicals with desired properties. The underlying assumption in these computational methods is that structurally similar molecules are likely to have similar biological and physicochemical properties (commonly called the similarity principle).5 Molecular similarity is a straightforward and easy-to-understand concept, but there is no absolute, mathematical definition of molecular similarity that everyone agrees on. As a result, there are a virtually infinite number of molecular similarity methods, which quantify molecular similarity. Similarity search uses a molecular similarity method to find molecules similar to the query structure.
1.4.1. Two-dimensional (2-D) similarity methods
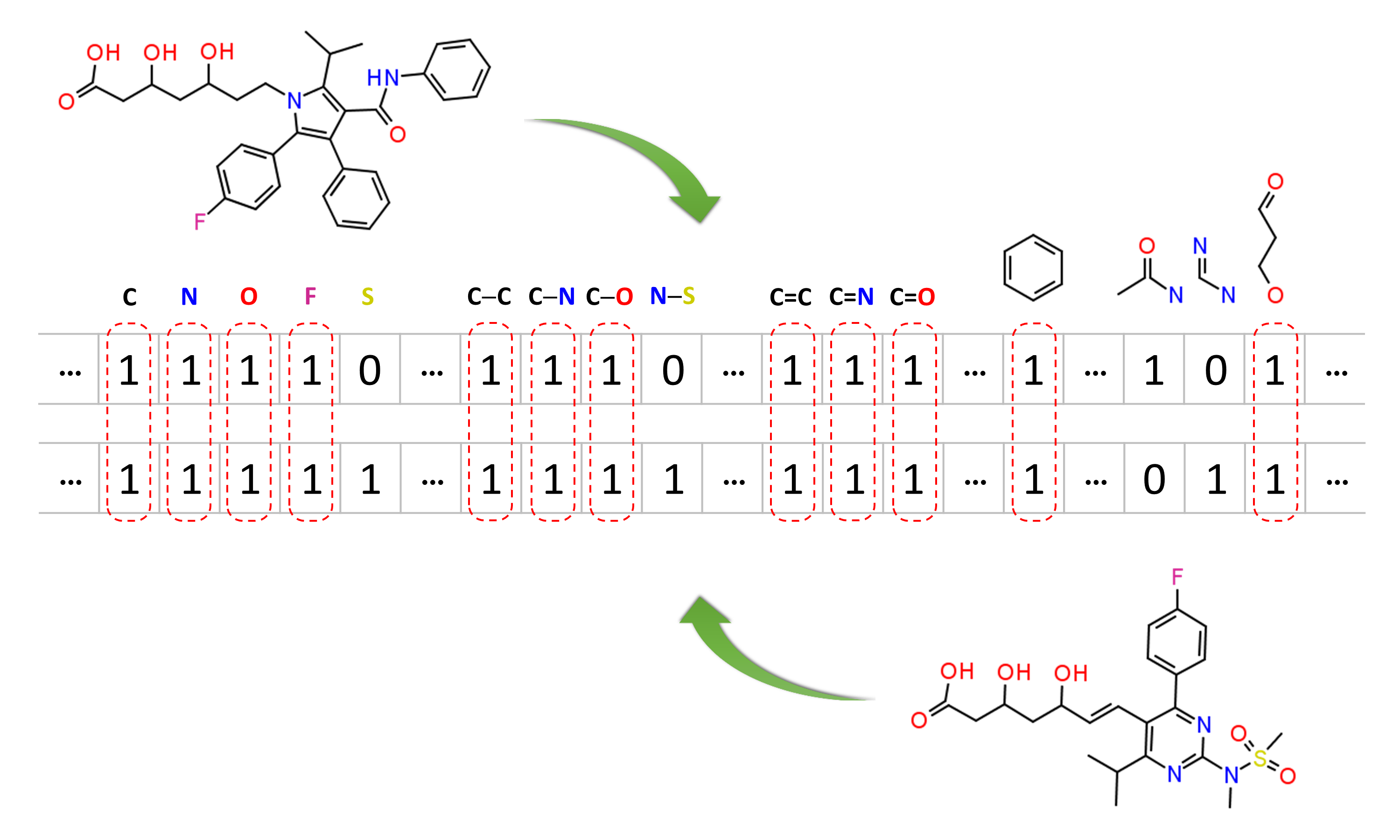
Molecular similarity methods can be broadly classified into two-dimensional (2-D) and three-dimensional (3-D) similarity methods. Typically, 2-D similarity methods use so-called molecular fingerprints. The most common types of molecular fingerprints are structural keys, which encode structural information of a molecule into a binary string (that is, a string of 0’s and 1’s). The position of each number in this string corresponds to a particular fragment. If the molecule has a particular fragment, the corresponding bit position is set to 1, and otherwise to 0. Note that there are many different ways to design molecular fingerprints, depending on what fragments are included in the fingerprint definition. PubChem uses its own fingerprint called PubChem subgraph fingerprints.
In 2-D similarity methods, structural similarity between two molecules is estimated by comparing their molecular fingerprints. Their similarity is quantified as a so-called similarity score or similarity coefficient. While several different methods can be used for computation of a similarity score, the underlying ideas are the same as each other: if the two fingerprints have 1’s at the same position, it means that both compounds have the same fragment, and if the molecules share more common fragments, they are considered to be more similar. In conjunction with the PubChem subgraph fingerprints, PubChem 2-D similarity method use the Tanimoto coefficient6-8
![]()
where NA and NB are the number of bits set in the fingerprints for molecules A and B, respectively, and NAB is the number of bits set in both fingerprints. The Tanimoto score ranges from 0 (for no similarity) to 1 (for identical molecules). 2-D Similarity search returns molecules whose similarity scores with the query molecule are greater than or equal to a given Tanimoto cut-off value.
1.4.2. PubChem 3-D similarity method
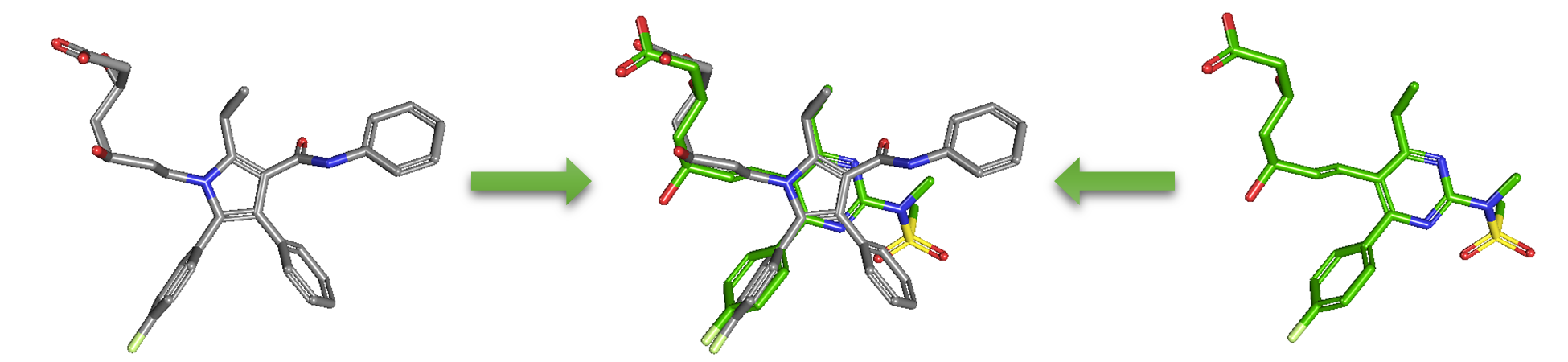
As an alternative to 2-D similarity search, 3-D similarity search can also be performed using the “3D conformer” tab in PubChem Chemical Structure Search. 3-D similarity methods use the 3-D structures (that is, conformations) of molecules. PubChem’s 3-D similarity method is based on the atom-centered Gaussian-shape comparison method by Grant and coworkers,9-12 implemented in the Rapid Overlay of Chemical Structures (ROCS).13,14 While the underlying mathematics of this approach is beyond the scope of this module, what this method essentially does is to find the “best” alignment of the 3-D structures of two molecules, which gives the maximized overlap between them. The 3-D similarity method quantifies the 3-D molecular similarity using three metrics.
- Shape-Tanimoto (ST): quantifies steric shape similarity between two conformers.
- Color-Tanimoto (CT): quantifies the overlap of functional groups between two conformers, such as hydrogen bond donors and acceptors, cations, anions, rings, and hydrophobes.
- Combo-Tanimoto (ComboT): the sum of ST and CT scores between two conformers. It takes into account the shape similarity (ST) and functional group similarity (CT) simultaneously.
Because both the ST and CT scores range from 0 (for no similarity) to 1 (for identical molecules), the ComboT score may have a value from 0 to 2 (without normalization to unity). Note that the ST, CT and ComboT scores between two molecules can be evaluated in two different molecular superpositions: (1) in the ST- or shape-optimized superpositions, and (2) in the CT- or feature-optimization superpositions. In the ST-optimization approach, the shape overlap between the molecules (that is, the ST score) are maximized and the single-point CT score is evaluated at that superposition. On the contrary, the CT-optimization considers both ST and CT scores to find the best superposition between molecules, and the single-point ST score is computed at that superposition.
The 3-D similarity method used in PubChem requires the 3-D structures of molecules. PubChem generates a conformer ensemble containing up to 500 conformers for each compound that satisfy the following conditions15-17:
- Not too big or too flexible (with £ 50 non-hydrogen atoms and ≤ 15 rotatable bonds).
- Have only a single covalent unit (i.e., not a salt or a mixture).
- Consist of only supported elements (H, C, N, O, F, Si, P, S, Cl, Br, and I).
- Contain only atom types recognized by the MMFF94s force field.
- Fewer than six undefined atom or bond stereo centers.
About 90% of compounds in PubChem have computationally generated conformer models. Although each compound has up to 500 conformers (depending on the molecular size and flexibility), many PubChem tools and services support up to 10 conformers per compound. It should be emphasized that these conformers are not energy-minimized but sampled from the conformational space of a given molecule in such a way that the sampled conformers represent the overall diversity of shape and feature of the molecule.15-17 These conformer models aim to generate bioactive conformers, which would be found in protein-ligand complexes. For this reason, these conformers are often very different from their experimental structures determined in the gas phase.
2. PubChem tools for cluster analyses
Cluster analysis or clustering18 divides a set of objects into groups (called clusters) so that the objects within a cluster are more similar to each other than to those in other clusters. While cluster analysis is widely used in many areas, its most common application in Cheminformatics is to grouping compounds according to their similarity in structures, molecular properties, biological activities or combinations of these. Because the similarity between molecules can be quantified in many different ways (as mentioned in the previous section), the result of clustering a set of compounds also depends upon how similarity among them are quantified. PubChem provides two web-based tools that allow users to perform a cluster analysis of PubChem data: the Structure Clustering tool and Structure-Activity Relationship (SAR) Analysis tool.
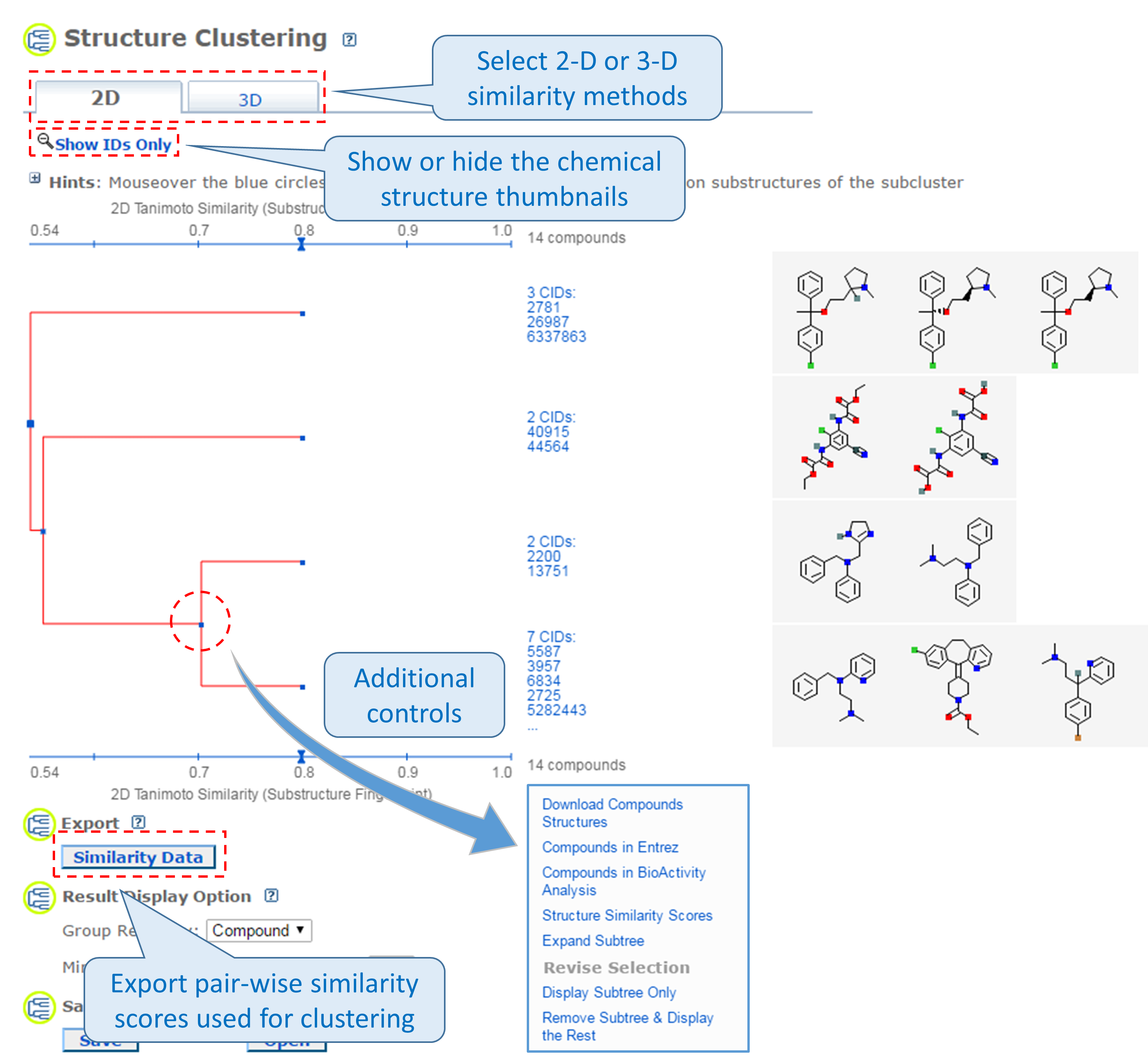
2.1. The Structure Clustering tool
PubChem’s structure clustering tool is available at this URL:
https://pubchem.ncbi.nlm.nih.gov/assay/assay.cgi?p=clustering
This tool allows users to cluster compounds based on PubChem 2-D or 3-D similarity and visualize the clusters in a dendrogram.19 The input compound list may be provided using a string, a text file, or Entrez history. The Structure Clustering tool computes similarity scores among the input compounds, which are subsequently used to cluster them through the single-linkage clustering algorithm20. These similarity scores can be downloaded in the .csv (comma-separated values) format, which may be open in a spreadsheet program (such as MS Excel or GoogleSheet). The thumbnail images of the compounds may be displayed next to the dendrogram, which help users visually inspect the structural similarity among them. The clustering threshold may be adjusted by clicking an appropriate position on the similarity score axis (the horizontal line above/below the dendrogram).
2.2. The Structure-Activity Relationship (SAR) Analysis tool
PubChem also provides the Structure-Activity Relationship (SAR) Analysis tool, available at the following URL:
https://pubchem.ncbi.nlm.nih.gov/assay/assay.cgi?p=heat
It presents biological activity data in a heat map-style layout,21 in which the rows and columns correspond to the compounds and the assays being considered. The compounds may be clustered by (either 2-D or 3-D) structural similarity or bioactivity similarity, and the assays may be clustered by similarity in the activity of tested compounds, target protein, depositor-specified related bioassays, or biosystems with the input assays. Essentially, this tool displays the bioactivity data along with the clustering results of the compounds and the assays in which they are tested. The SAR analysis tool helps users determine the common structural factor(s) among compounds that have similar biological activities against the target protein.

References
(3) Kim, S. Expert Opinion on Drug Discovery 2016, 11, 843.
(4) Ihlenfeldt, W. D.; Bolton, E. E.; Bryant, S. H. J. Cheminform. 2009, 1, 20.
(6) Chen, X.; Reynolds, C. H. J. Chem. Inf. Comput. Sci. 2002, 42, 1407.
(8) Holliday, J. D.; Salim, N.; Whittle, M.; Willett, P. J. Chem. Inf. Comput. Sci. 2003, 43, 819.
(9) Grant, J. A.; Pickup, B. T. Journal of Physical Chemistry 1995, 99, 3503.
(10) Grant, J. A.; Gallardo, M. A.; Pickup, B. T. Journal of Computational Chemistry 1996, 17, 1653.
(11) Grant, J. A.; Pickup, B. T. Journal of Physical Chemistry 1996, 100, 2456.
(14) 3.1.0 ed.; OpenEye Scientific Software, Inc.: Santa Fe, NM, 2010.
(16) Bolton, E. E.; Kim, S.; Bryant, S. H. J. Cheminform. 2011, 3, 4.
(17) Kim, S.; Bolton, E. E.; Bryant, S. H. J. Cheminform. 2013, 5, 1.
(18) Cluster analysis (https://en.wikipedia.org/wiki/Cluster_analysis) (Accessed on March 10, 2017).
(19) Dendrogram (https://en.wikipedia.org/wiki/Dendrogram) (Accessed on March 10, 2017).
(20) Single-linkage clustering (https://en.wikipedia.org/wiki/Single-linkage_clustering) (Accessed on March 10, 2017).
(21) Heat map (https://en.wikipedia.org/wiki/Heat_map) (Accessed on March 10, 2017).
Questions
- To perform an identity search for Cymbalta (CID 60835), go to the Chemical Structure Search page (https://pubchem.ncbi.nlm.nih.gov/search/search.cgi) and select the “Identity/Similarity” tab. Expand the “Options” section by clicking the “plus” button and select the “Identical Structures” with “same connectivity” from the drop-down menus. Expand the Filters section and limit the number of covalent units to 1 (by setting the range to “from 1 to 1”). Provide the query CID in the search box and run the search. Repeat the search with the “same isotopical labels” option selected. Explain how the two different options affect the identity search results.
- Perform a 2-D similarity search using CID 5090 as a query. Select the “Identity/Similarity” tab and expand the Options sections by clicking the “plus” button next to the “Options” section heading. Select the “Similar Structures” and “95%” from the drop-down menus. Expand the Filters section and limit the number of covalent units to 1. Provide the CID query in the search box and press the “search” button. Repeat the search with the following similarity search threshold: 90%, 85%, and 80%.
- How many records are returned for each search?
- The right column of the last search result page (for threshold >= 80%) shows what kind of information is available for the returned compounds. Click the “Pharmacological Actions” link under “BioMedical Annotation” to choose the compounds with the Pharmacological Action annotations. For each compound, check the information under the “Pharmacology and Biochemistry” section. What pharmacological actions do these compounds have?
- Select the “3D Conformer” tab to perform a 3-D similarity search using CID 5090 as a query. Expand the Options section and select the “(Sort results by) Shape-then-feature” and “(output to) NCBI Entrez” options from the drop-down menus. Expand the Filters section and limit the covalent unit count to 1. Type the query CID in the search box and press the “search” button. How many compounds are returned? How many CIDs have pharmacological action annotations. Compare the results from 3-D similarity search with those from 2-D similarity search.
- How many records are returned for each search?
- In this question, you will learn how to explore PubChem’s bioactivity data.
- Search the PubChem Compound database for seretide, without any Entrez index specified. Initially, you will get more than a thousand compounds because the auto-correction functionality of the search system will modify the query to “selenide”. Make sure that you search for “seretide”, by clicking “seretide” in the message “Search instead for seretide” presented at the top of the DocSum page. How many compounds are retrieved? What are their CIDs?
- Go to the Compound Summary page for each compound in (a) and retrieve its component compounds by clicking the “Mixtures, Components, and Neutralized Forms” item in the “Related Compounds” section. What are the CIDs for the component compounds for each compound in (a).
- What is the common component that appears in all compounds retrieved in (a)? What are the non-common components that occur in only one of the compound in (a)? What is the difference between the non-common components of the compounds in (a)?
- Go back to the DocSum page for the search for “seretide”, and retrieve their component compounds by selecting “PubChem Compound” -> “Mixture/Component Compounds” from the drop-down menu under the “Find Related Data” on the right column. This directs you to the DocSum page that presents all components you retrieved in (b). Refine the list by selecting only those with pharmacological actions annotations (available under the Biomedical annotation on the right column). What are the CIDs of these compounds? What are the names of these compounds used as the titles of their Compound Summary page?
- For each compound in (d), go to the “Pharmacology” section of its Compound Summary page and find the target receptor to which the compound bind
- Find compounds that are more potent than the compounds in (d) against the same targets, using the following steps:
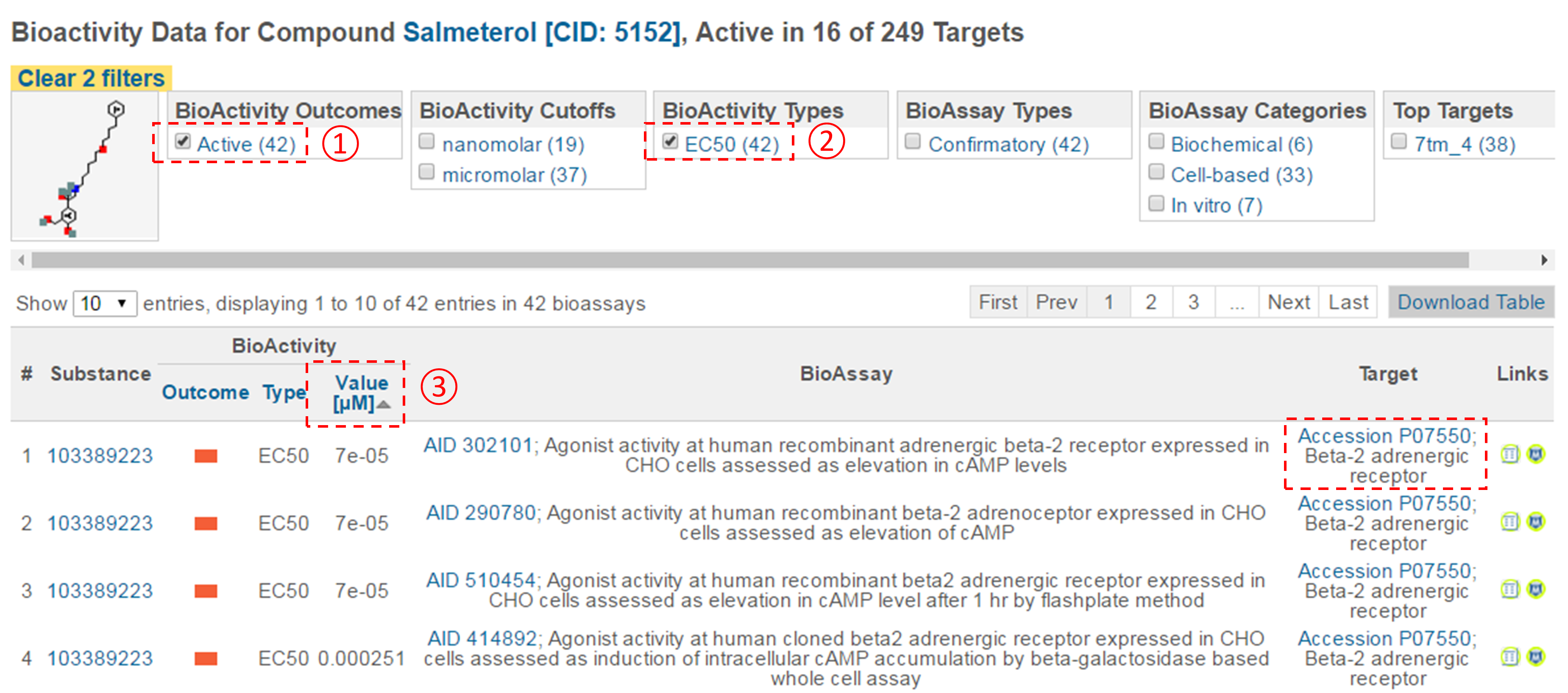
- For each compound in (d), go to the “BioAssay result” section of its Compound Summary page. This section displays bioactivity data for the compound in a tabular format. Click the “Refine/Analyze” button above the top-right corner of the table to go to the Bioactivity analysis tool. This directs you to the page that allows you to filter the bioactivity data by various criteria. How many targets has this compound been tested to be active against? [It’s mentioned at the top of the page.]

- Filter the bioactivity data by selecting “active” for the bioactivity outcome and “EC50” for the BioActivity types. Sort the table by EC50 value in ascending order. What is the target name and accession for the bioactivity data that appear at the top of the sorted list (that is, the target of the compound with the smallest EC50 value)?
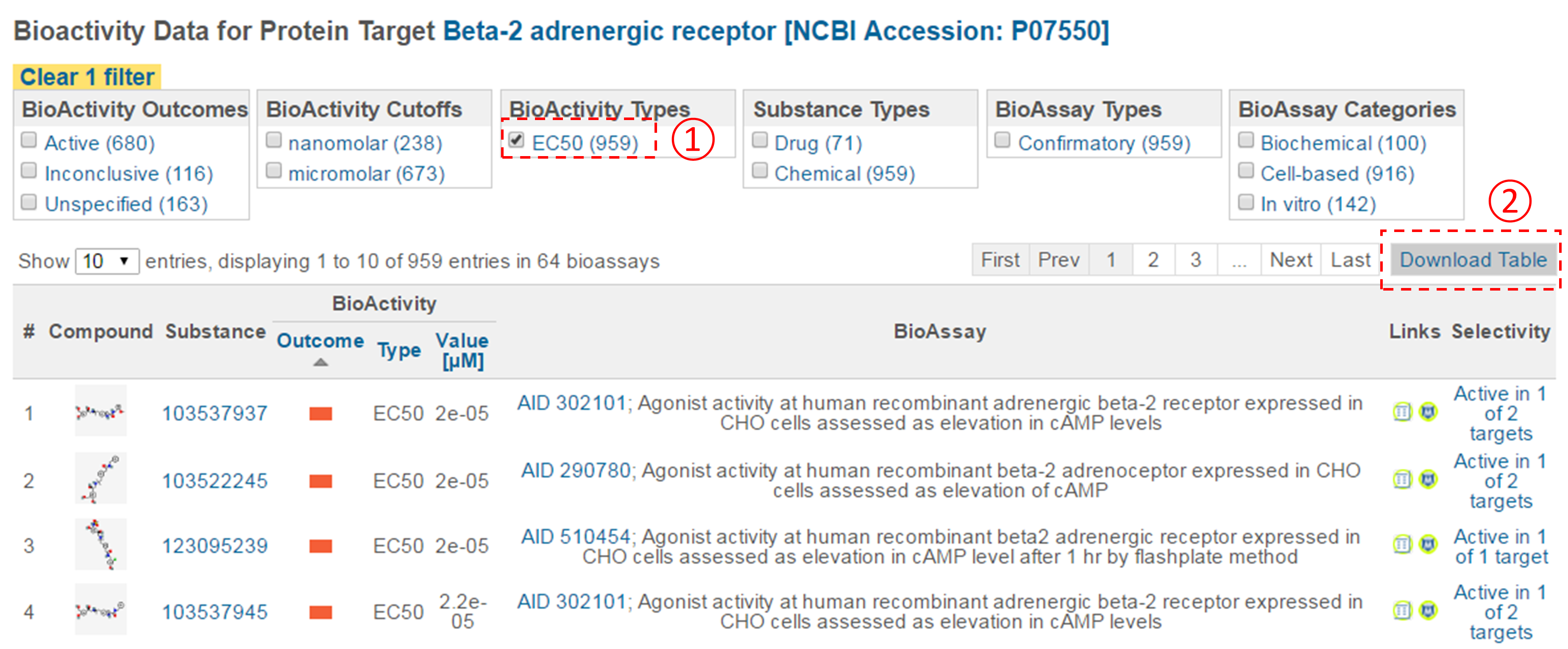
- Click the accession number of the target in (ii) to go to the page that presents all bioactivity data against the target. Filter the data by selecting “EC50” for the bioactivity type, and click the “Download Table” button at the top-right corner of the table to download the selected data in a tab-delimited txt file. Open this file in Excel (or Google Sheet) and sort the table by AC value in ascending order (from smallest to largest). How many compounds are more potent than the CID in (d) (that is, those with smaller EC50 values)? [Note that a compound may have multiple EC50 values determined from different experiments (likely under different experimental conditions). Therefore, one often needs to check all available experimental values to choose the most reasonable value to use in subsequent analysis. In this homework question, use the smallest EC50 value (for simplicity) if there are multiple values.]
- For each compound in (d), go to the “BioAssay result” section of its Compound Summary page. This section displays bioactivity data for the compound in a tabular format. Click the “Refine/Analyze” button above the top-right corner of the table to go to the Bioactivity analysis tool. This directs you to the page that allows you to filter the bioactivity data by various criteria. How many targets has this compound been tested to be active against? [It’s mentioned at the top of the page.]
- Search the PubChem Compound database for seretide, without any Entrez index specified. Initially, you will get more than a thousand compounds because the auto-correction functionality of the search system will modify the query to “selenide”. Make sure that you search for “seretide”, by clicking “seretide” in the message “Search instead for seretide” presented at the top of the DocSum page. How many compounds are retrieved? What are their CIDs?
- This question is designed to help you understand how various tools in PubChem can be used together to analyze the bioactivity data of a group of chemicals.
- Go to the Classification Browser (https://pubchem.ncbi.nlm.nih.gov/classification) and select “MeSH” for classification, “Compound” for data type counts to display, and “No” for whether to display zero count nodes. Then select the Anti-allegic agent node from the MeSH tree (by clicking Chemical and Drug Category → Chemical Actions and Use → Pharmacological Actions → Therapeutic Uses → Anti-allergic agent). How many compounds do you get?
- Some of the compounds retrieved in (a) contain active drug ingredients as well as their salt and mixtures. For simplicity, limit the search only to monomeric, neutral molecules without minor isotopes by combining the retrieved search results [from (a)] with the following Entrez indices:
- 1:1[CovalentUnitCount]
- 0:0[IsotopeAtomCount]
- 0:0[TotalFormalCharge]
How many compounds do you get?
- Click the “Structure Clustering” button near the top of the right column, to get the dendrogram that shows the compounds in (b) clustered into small groups at the clustering threshold of 0.9 (in terms of PubChem 2-D similarity). Click the “Show 2D thumbnails” button under the “2D/3D” tabs to show the 2-D images of the molecules next to the dendrogram. Click the midpoint (~0.65, not necessarily exact) between 0.6 and 0.7 on the similarity score axis (the horizontal line above/below the dendrogram).
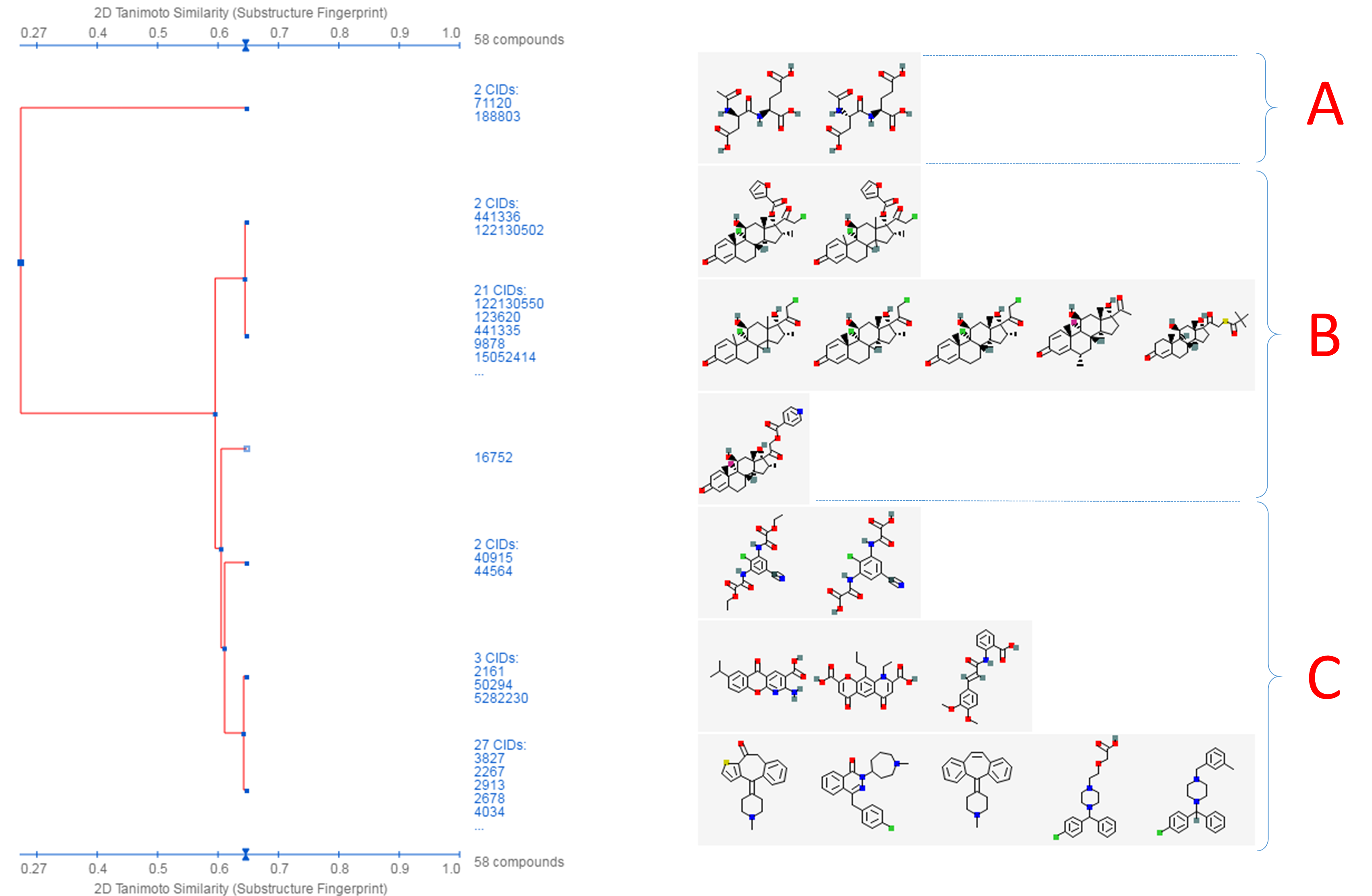
- From the dendrogram, you can see that the compounds can be classified roughly into three groups. Group A has two compounds, CIDs 71120 and 188803. These are “dipeptides”, which have two amino acids connected with a peptide bond. For convenience, duplicate this web page in a new window to avoid generating the page again. Click the blue circle on the node (on the dendrogram) that corresponds to group A, and then “Compounds in Entrez”. Go to the Compound Summary pages of these compounds and find their IUPAC-condensed biologic line notations and record them below. What are the relationship between these two compounds?
- Go back to the dendrogram page and duplicate it again in a new window. Group B includes 24 compounds. Click the parent node of the two biggest clusters (with 21 CIDs & 2 CIDs, respectively), and then the “Compounds in Entrez” link to go to the DocSum page that presents the 23 CIDs. Click “All 5 pharmacological actions” under the BioMedical annotation section on the right column. What are the five pharmacological actions associated with at least one of these 23 compounds? Provide a short description about each pharmacological action (you can copy and paste the descriptions presented on the MeSH DocSum page).
- Go back to the dendrogram page and duplicate it again in a new window. Click the parent node of all clusters containing the Group C compounds. (32 CIDs) and then the “Display Subtree Only” link to present only the 32 CIDs on the dendrogram. Click the “Export Similarity Data” below the dendrogram (near the bottom of the page) to download (in .csv format) the 2-D similarity scores among the 32 compounds used to generate the dendrogram. Click the 3-D button of the dendrogram to generate a new dendrogram using 3-D similarity scores. Download the 3-D similarity scores by clicking the Export Similarity Data” button below the dendrogram. After opening the two downloaded score files in Excel or Google Sheet, compute the difference between the 2-D and 3-D similarity scores for each CID pair, using the following equation:
Δ = (3-D score) / 2 – (2-D score).
Note that the 3-D similarity score is divided by 2, because it ranges from 0 to 2, while a 2-D similarity score can range from 0 to 1. Report the CID pair with the smallest Δ value (which means that the pair has a small 2-D score but a large 3-D score). Also report the CID pair with the largest Δ value (which has a large 2-D score, but a small 3-D score).
(CID1, CID2)
2-D score
3-D score
Δ[= (3D/2) - 2D]
- Go to the PubChem home page (https://pubchem.ncbi.nlm.nih.gov) and click the “Structure Clustering” button available on the right column. Using the CIDs from (iii) as inputs to the Structure Clustering tool, generate a dendrogram based on 3-D similarity score. Clicking the node for the cluster that contains the CID pair from (iii) and then “Compounds in 3D Viewer” to visualize the 3-D superposition of the two compounds. Briefly describe the complementarity between 2-D and 3-D similarity methods, using the conformer pairs from (iii) as an example.
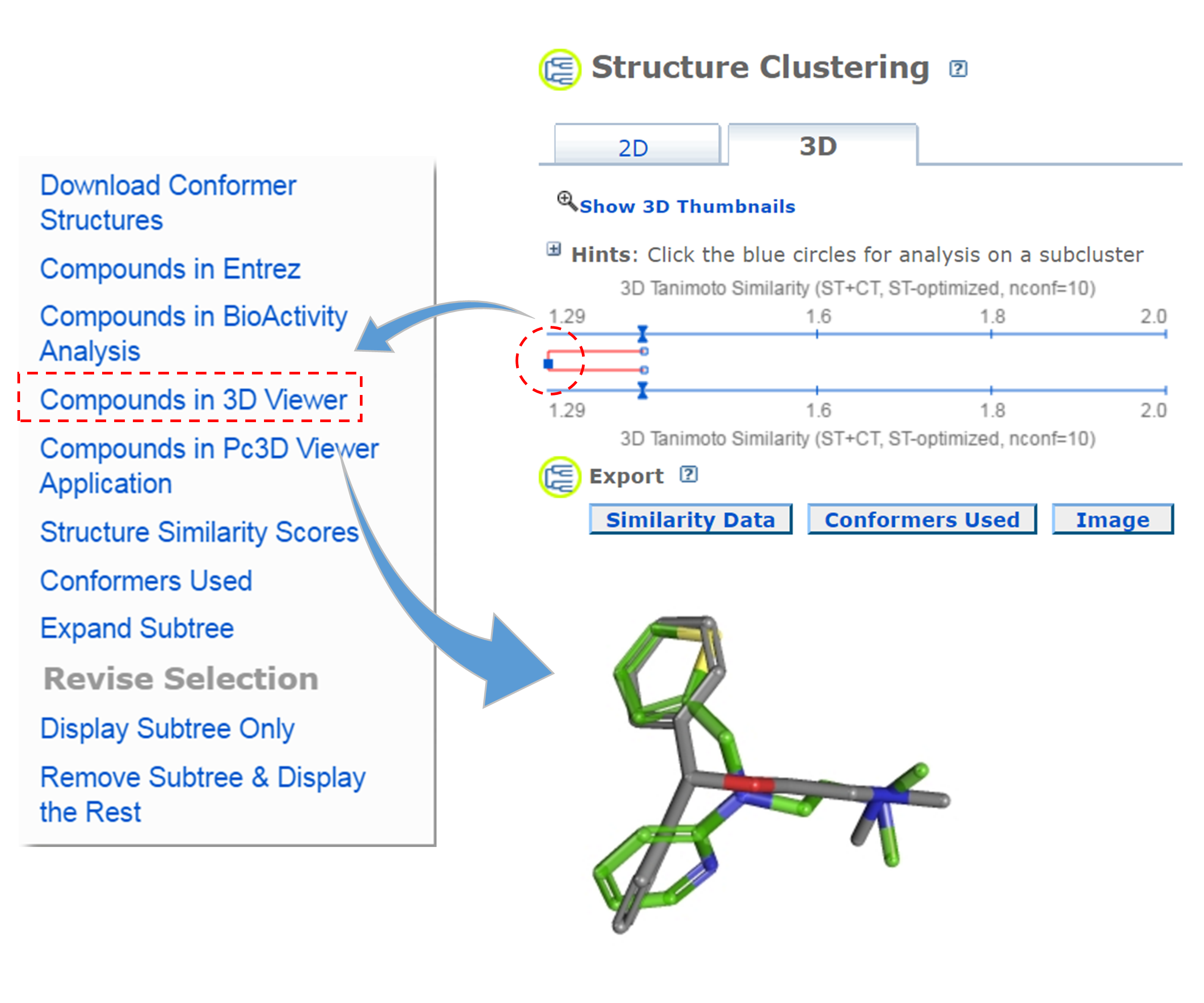
- From the dendrogram, you can see that the compounds can be classified roughly into three groups. Group A has two compounds, CIDs 71120 and 188803. These are “dipeptides”, which have two amino acids connected with a peptide bond. For convenience, duplicate this web page in a new window to avoid generating the page again. Click the blue circle on the node (on the dendrogram) that corresponds to group A, and then “Compounds in Entrez”. Go to the Compound Summary pages of these compounds and find their IUPAC-condensed biologic line notations and record them below. What are the relationship between these two compounds?
- Go back to the search result page from (b). Through “Find Related Data”, retrieve assays in which any molecules being considered are found to have a submicromolar potency. The retrieved AIDs may or may not have protein target information (for example, for some assays performed on whole cells or organisms without specific target macromolecules). Select those with the target information by clicking “Proteins” under the “Targets” part of the “Refine your results” section at the top of the right column.
- Go to the PubChem home page and then click the “BioAssay Tools” -> “SAR” buttons on the right column. Select the compound search history from (b) and the assay search history from (d) as input CIDs and AIDs. Then click the “Go” button. When a heat map of the bioactivity data is displayed, select “Protein target” similarity for “Cluster BioAssays by” and “Activity (IC50 etc.)” for “Activity Data” and click the “Apply” button. The rows of the heat map correspond to tested compounds and the columns represent the proteins against which the compounds were tested. The legend near the top-left corner of the heat map explains how bioactivity data are color-coded. (Basically, red/orange mean “strong activity against the target” against the target, and green/blue mean “weak activity against the target”. Grey means no data available or not tested.) Answer the following questions.
- Many anti-allergic drugs are classified as anti-histamines because they opposes the activity of histamine receptors. From the heat map, find the region that show bioactivity data against histamine receptors. How many blue or green cells exist in this region of the heat map?
- About 25% of compounds displayed in the heat map do not have bioactivity data against histamine receptors. What compound group [from (c)] do these compounds belong to?
- From the heat map, find the high-activity cells (red/orange regions) for the compounds in (ii) against the protein GIs (numeric identifiers presented at the top axis of the heat map) listed in the table below and record the names of the proteins.
GI
Protein name
348019672
311348376
124375976
- Search the web for one known endogenous ligand (as an example) for each protein in (iii), and provide the structure below (you are allowed to copy and paste the images of the ligands).
- Explain why compounds in (ii) have strong activities against the proteins in (iii).
- Neutrotransmitter receptors (such as adrenergic receptors, dopamine receptors, serotonin receptors, and muscarinic acetylcholine receptors) play an important role in the central nervous system. Among the three compound groups in (c), which one shows a strong activity against these receptors?
- Read the first paragraph of this Wikipedia article about hERG protein (https://en.wikipedia.org/wiki/HERG), and explain (in two or three sentences) what the role of this receptor is in the human body and why this target is important in drug discovery and development.
- From the heat map, find the compounds with the strongest activity against the hERG protein. What is the CID of this compound? Go to the Compound Summary page of this compound and review the information in the “7. Drug and Medication Information”. Write a paragraph (of no more than 5 sentences) that includes the following information:
- CID and chemical name of this compound
- Intended uses/indications of this compound.
- Summary of adverse side effects
- Explanation of the underlying mechanism for the adverse side effects.
- Current marketing status of this compound
- Many anti-allergic drugs are classified as anti-histamines because they opposes the activity of histamine receptors. From the heat map, find the region that show bioactivity data against histamine receptors. How many blue or green cells exist in this region of the heat map?
- Go to the Classification Browser (https://pubchem.ncbi.nlm.nih.gov/classification) and select “MeSH” for classification, “Compound” for data type counts to display, and “No” for whether to display zero count nodes. Then select the Anti-allegic agent node from the MeSH tree (by clicking Chemical and Drug Category → Chemical Actions and Use → Pharmacological Actions → Therapeutic Uses → Anti-allergic agent). How many compounds do you get?
Comments 26
Numbering in the Homework questions has been corrected.
On March 23, 2017.
The question numbers in the old version was confusing, so I've corrected numbering in the Homework questions on this Module 6 web page. And a corrected version of the .docx file for the Module 6 assignments (2017OLCCModule6Assignment.docx) has also been uploaded, which is available at the top of this page.
(In the corrected version, Question 2, which has sub-questions (a), (b), and (c), is followed by Question 3. However, in the old version, the sub-questions of Question 2 were mistakenly labelled as 1, 2, and 3, and Question 3 as Question 4. Similar mistakes were made in several places in the old version. These errors are corrected in the new version. All questions are exactly the same as the old ones, except for the question numbers/labels.)
Gaussian Shape Comparison
There are two perspectives on the use of Gaussian Shape
There are two perspectives on the use of Gaussian functions to describe the shape of molecules.
(1) We often use a hard-sphere model to visualize a molecule (in which a hard-sphere is placed at the position of the atoms), because it gives you a clear idea about whether an atom is located in the molecule and how big it is. Overall, the position of these hard-spheres will represent the shape of a molecule. However, this is a simplified view because an atom is *not* a hard sphere. Rather, the atom is "soft", in the sense that the distribution of electrons in an atom (represented by electron density) diminishes as it goes away from the nucleus, but never becomes zero, forming a very long tail. The use of Gaussian functions instead of hard-spheres to describe molecular shape somehow reflects this view, although it is true that the shape will be blurred. But it's the nature of electrons, too.
(2) There is a more practical reason to use Gaussian shapes over hard-spheres. When you superimpose hard-sphere models of molecules to compute the overlap between the two shapes, it is not easy to deal with the "cusp" where the two hard-spheres meet. However, when Gaussian functions are used, you can calculate the overlap between them very easily and quickly, because the Gaussian functions have a unique property that the product of two Gaussian functions are another Gaussian.
So, overall, it is true that the use of Gaussian functions will blur the molecular shapes, but it is actually close to the "soft" nature of atoms. But, the primary advantage (or reason) for using Gaussian functions is to speed up the computation of molecular overlap.
Question 2
It's a problem with histories cached in your browser.
If you encounter an error message saying something like "History Not Found", it typically means that there is an issue with the histories cached in your browser. In practice, you can try three things.
(1) Try a different browser (e.g., Chromes, IE, Edge, Safari, Firefox, ... any browser you haven't encountered the problem). This is the simplest solution that I recommend.
(2) the second option is to delete all caches stored in your browser to clear up your previous entrez histories.
(3) Entrez histories will expire after some period of inactivity (I believe, 8 hours of inactivity). In other words, if you don't use any NCBI resource (through Entrez) for 8 hours, the problematic histories will be expired and everything will go back to normal.
Let me know whether the issue is resolved or not.
Sunhwan,
In doing question 4 part C.
my real question
No, you can't.
>> Can you use Tanimoto coefficients to identify stereoisomers? No you can't. Pubchem fingerprint does not contain all possible fragments in its fingerprint definition. Even if two molecules have a similarity score of 1, they may differ in the absence/presence of a fragment that is not pre-defined in PubChem fingerprint. And there is no guarantee that this fragment has anything to do with stereochemistry.
>> is this the crux of 2D and 3D similarity are different? (or one of the major reasons)?
Most studies that compare 2-D and 3-D methods focused on how they are different in terms of performance (e.g., how many hits are identified or how many hits are unique to one method or common to both, etc.), but these studies were not designed to study why they give different results. So, there is no good answer to your question. However, in my view, the way in which 2-D fingerprint-based method encode molecular structures is completely different from 3-D similarity methods, and this difference make 3-D methods to recognize molecular similarity that 2-D methods can't. (Of course, PubChem's 2-D and 3-D similarity methods are not reprentatives of many existing 2-D and 3-D similarity methods, so we would end up different conclusions if we use different methods).
Imperfection of molecular descriptors
Any similarity methods has two important components:
(1) Molecular descriptors that describe the structure of molecules and
(2) Metric that quantifies molecular similarity by comparing molecular descriptors that represent two molecules.
Ideally, isomers (whether they are stereoisomers, constitutional isomers, or enantiomers ...) are different in "some" context. So if you have a "perfect" molecular descriptor (meaning that it can describe the difference between various isomers), you would expect that these isomers would have different molecular descriptors. However, no molecular descriptors are perfect, they often lead to the same set of molecular descriptors for different molecules. The molecular descriptor used in this homework (PubChem fingerprints) does not contain any information on stereochemistry (in other words, no bit position in the fingerprint encodes stereochemistry information). Actually, many commonly-used fingerprints do not encode stereochemistry and isotopism, so the similarity comparision using these fingerprints cannot distinguish stereoisomers or isotopomers. To demonstrate the consequence of this "artifact", compute the 2-d similarity score for CID 10900, 643833, 638186 (using the Score Matrix Service: https://pubchem.ncbi.nlm.nih.gov/score_matrix/score_matrix.cgi). (They are 1,2-dichloroethene). You will get the similarity score of 1 for all possible pairs from three compounds.
For Group B Compounds in this homework question, some of them are isomers and others are not, because they have different substituents. However, all of them have a common structural unit (four-membered ring), which is a structural characteristic of steroids compounds. So, we say that these compounds have the same (molecular) scaffold. The similarity scores used for the dendrogram are available through the buttom "Export Similarity data" below the dendrogram. If you look at these scores you will realize they do have very high similarity scores. (Actually, to solve question 4-c-iii, students need to download the similarity scores and analyze them).
Tanimoto coefficient
In the last figure below on
PubChem Fingerprints are (Base-64) encoded binary numbers
>> Is the dendrogram the fingerprint?
No. The phrase "substructure fingerprint" within parentheses is a part of the axis title "2-D Tanimoto Similarity (substructure fingerprint)".
>> I am unfamiliar with bytes and bits.
Well, a bit is a "binary" digit (that is, it can be either 0 or 1). Two-digit binary numbers (11, 10, 00, 01) are 2-bit long, and three-digit binary numbers (111, 110, 101, ..., 000) are 3-bit long. One byte is equal to 8 bits, means that it can be 11111111 ~ 00000000.
>> what does a fingerprint look like?
PubChem fingerprints are a 881-long sequence of 0's and 1's. In practice, it is too long, we encode this string of 0's and 1's into a base-64 integer (See Table 1 of this webpage: http://www.faqs.org/rfcs/rfc3548.html). Conceptually, it is very similar to conversion of binary numbers to hex-numbers. Hex-numbers use 16 digits (0~9 and A,B,C,D,E,F) to encode binary numbers. Similarly, Base 64 numbers use 64 digits (listed in Table 1 of the webpage http://www.faqs.org/rfcs/rfc3548.html). Consider that Base16- or Base64-encoding is just one way to "compress" fingerprints, which are binary numbers.
Well, I googled some introductory material for this topic, and I hope these two material would help you better understand it.
http://computer.howstuffworks.com/bytes.htm (please go through all five pages on this web document) https://web.njit.edu/~walsh/powers/bits.vs.bytes.html
Question on comparing 2D/3D
See my comment below
It's actually simple.
The primary issue is that the rows and columns in the two files are not sorted in the same way. Please follow these steps.
[1] For 2-D similarity score matrix.
(1a) Select all data and sort the data by the first column (that is, CIDs) in ascending (increasing) order. Now your *columns* are sorted by CID.
(1b) Transpose the whole matrix (e.g., switch the rows and columns). To do this, select the whole matrix and copy it into clipboard (Ctrl+C). Then, paste it using "paste special"->"transpose" option. Because you transposed the columns/rows, now your *rows* are sorted by CID.
(1c) Sort the columns by CID in ascending order [as you did in (1a)]. Now both columns and rows of the 2-D score matrix is sorted by CID.
[2] Sort the 3-D score matrix in the same way you did in [1].
[3] Now, both 2-D and 3-D score matrices are sorted in the same way. Place the two matrices side by side, by copying and pasting one of them to the other spread sheet.
[4] Now you can compute the difference between the elements in the two matrices.
[5] Use the max() and min() functions to find the extreme differences. (It would be helpful if you compute the max. and min. values for each row and column first, then the values for the whole matrix.)
Problem with 2D and 3D Data
See the above comment.
AIDs
Submicromolar means "less than micromolar"
4ci
The biological line notations for the two compounds are...
Sorry for this delayed reply. I don't know why, but this platform did not post my reply that I made previously.
Long story short,
=== The biological line notations for the two compounds are:
CID 71120 : Ac-D-Asp-Glu-OH
CID 188803 : Ac-Asp-Glu-OH
===
Sorry that the biological line notations for these two compounds have been removed by a filter that PubChem introduced to remove biological notations for non-biologic molecules. This filter has an accuracy of 90%, but the two compounds used in this homework happened to be removed.
Question on Covalent units.
About limiting the covalent unit counts
how can we get the region
It is from question 4 e (i).
How many blue or green cells exist in this region?
>> How many blue or green cells exist in this region of the heat map?
This is the question that you will need to answer, after finding the group of assays that target histamine receptors. (You don't need to report AIDs/GIs (because you were not asked to report.) If you still don't have a good idea, think about what anti-histamines are and what the blue/green color means.