One common way to offer open data to be used programmatically is through a web API. Before digging into the most relevant chemistry APIs, we will spend a moment discussing some technological aspects that should be known in order to use it.
What’s a web API?
An API (Application Programming Interface) is the set of elements that a programming library or service makes available to other programmers to be used remotely to access their services and data.
This API is called a web API when these functionalities are delivered via the HTTP protocol through the Internet.
How is a web API used?
In order to be able to get information from an online database, we will need to:
1.Send a query to the database through the Internet (HTTP protocol)
2.Understand the format in which the response will be received
3.Process this response to extract the desired information
Sending the query... - The HTTP protocol and the REST architecture
HTTP stands for HyperText Transfer Protocol and it comprises the set of rules that control the transfer of a resource between a web server and a web client (usually a browser).
The basic elements of an HTTP transaction are:
●A request message
●A response message (which is usually the resource being transferred)
The HTTP request message
The request message consists in some text data sent to an URL (Uniform Resource Locator). A URL is a way of specifying an address in the Internet.
The general structure for an URL consists of
scheme://[user:password@]domain:port/path?query_string#fragment_id
although in HTTP this commonly simplified to
http://domain/path or https://domain/path
The request message, which is usually handled by the HTTP client, has the following structure
●A first line which includes method, path and HTTP protocol version, usually
METHOD /path HTTP/x.x
●Several header lines
●A blank line
●And an optional message body
The HTTP request methods: GET and POST
Although other methods exist, the most common request methods are GET and POST.
In the GET method, any additional information required to specify the request is included in the URL (which means in the path included in the first line of the message). The parameters are included after the path and a question mark as pairs name=value. Parameters are separated by the ampersand symbol (&)
/path?name1=value1&name2=value2
In some cases, as we will see in PubChem API, the parameters are included in the path. This technique is called URL rewriting and shortens the URLs and makes it more usable.
/path/name1/value1/name2/value2
or even
/path/value1/value2
In POST methods, any additional information is not included in the URL but in the body of the message and is usually submitted via a web form. We won’t go further into this method since most of the chemistry APIs can be queried via GET calls.
To end this brief introduction to HTTP, note that some characters are either disallowed or have special meaning in URLs. When these characters appear they will need to be encoded; for example a space is encoded as %20, and a sharp (#) is %23. A reference can be found at http://www.w3schools.com/tags/ref_urlencode.asp.
The HTTP response message
As we have seen for the request, the response contains:
●A first line
●Several header lines
●A blank line
●And a message body which is the transferred resource
Two aspects of the response to be highlighted are the status code (included in the first line) and the content-type information (which is one of the headers).
HTTP status codes are indicated as a three-digit number
●200 means transaction completed successfully
●3xx means some type of redirection
●4xx means a client-side error
○404 means resource not found
●5xx means a server-side error
○500 means unexpected server error
The content type parameter indicates what data is included in the message body. Each type of resource is indicated with a standardized string (Internet media type; aka MIME type). For example, some common response formats are
●HTML file: text/html
●XML file: application/xml or text/xml
●CSV file: text/csv
●JSON file: application/json
●PNG image: image/png
Querying the databases
We have so far seen how the information is transmitted over the WWW. But how are databases accessed over the WWW? There are two main architectures used to access databases over the Net: SOAP and REST. Given its prevalence, we will center our discussion on the REST architecture.
Some major characteristics of the REST (REspresentational State Transfer) architecture are:
●It is usually implemented over HTTP.
●The queries are implemented as GET requests.
●The communication is stateless. Any query must contain all required information. Nothing is saved in the server.|
●The query result is obtained as a response in a predefined format: XML, JSON, CSV, HTML, plain text...
Further reading
●http://code.tutsplus.com/tutorials/http-the-protocol-every-web-developer-must-know-part-1--net-31177
●http://code.tutsplus.com/tutorials/a-beginners-guide-to-http-and-rest--net-16340
●https://www.addedbytes.com/articles/for-beginners/url-rewriting-for-beginners/
●https://www.iana.org/assignments/media-types/media-types.xhtml|
●http://www.restapitutorial.com/
Understanding the responses... - Common structured data file types
Common formats in which a web API may provide its response are HTML, XML, CSV, JSON and plain text. A short explanation of the first four types follows next. Feel free to skip it if you already know their characteristics.
HTML (HyperText Markup Language)
HTML is the standard language used to create web pages. When a web API outputs its result in HTML, this resource is usually intended to be viewed a browser. When no better option is available, HTML can be processed (parsed) to extract a specific information.
Likewise, any web page is published as HTML and so can be processed to extract any relevant information contained therein.
An example of HTML can be found here: http://kinetics.nist.gov/janaf/html/Cl-054.html
This the output of a search in the NIST-JANAF Thermodynamical Tables online database. The full HTML code can be read looking at the source of the page. A fragment is reproduced in Figure 1.


Figure 1. Part of the HTML code of a page
More information on HTML can be found at http://www.w3schools.com/html/.
XML (eXtensible Markup Language)
XML is a markup language designed to contain structured data in format easy to be read by computers and for humans. An example of an XML response can be found running the following query: https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/1/property/MolecularFormula,MolecularWeight,InChIKey/XML. Figure 2 shows its response.

Figure 2. An XML response
More information on XML can be found at http://www.w3schools.com/xml/.
CSV (Comma Separated Values)
CSV, for Comma Separated Values, is a plain-text file format used to store tabular data. In practice, CSV is not a unique format but different variations depending on the implementation and the regional setup of the operating system.
CSV main features:
●Data is stored as plain text.
●Records are separated by new-line characters.
●Each record contains several fields. Columns (fields) are separated by a delimiting character (usually a comma, a semicolon or a tab).
●Each record must have the same number of fields.
CSV main variations:
●Any encoding may be used for the text file: ASCII, Latin-1, UTF-8...
●Values may be quoted or not.
●End-of-line character, delimiting character, quotes and escaping sequences may vary.
●There may be header lines.
An example of a response in CSV is obtained when running the following query http://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/1000,1001/assaysummary/CSV.
The response is shown in Figure 3.
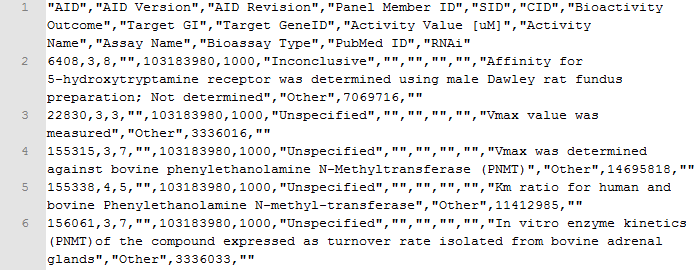
Figure 3. Fragment of a CSV response
More information can be obtained at https://en.wikipedia.org/wiki/Comma-separated_values.
JSON (JavaScript Object Notation)
JSON, for JavaScript Object Notation, is a format that encodes data object as human-readable text, organized as pairs attribute-value (name:value). Its main features are being a quite compact notation with easy conversion to Javascript objects (eval(), JSON.parse()).
An example query is https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/name/aspirin/property/MolecularWeight/JSON. The response is shown in Figure 4.

Figure 4. A JSON response
More information can be found at http://www.json.org/.
Processing the responses... - Parsers and string functions
Ultimately the response will need to be processed to extract the desired information. This can be done using specific functions or parsers or through the use of some simple string manipulation functions.
Sometimes you want to parse XML or HTML using custom string functions for deleting whitespace, finding the position of certain characters within strings and for extracting substrings. These functions (plus many more) appear in all commonly used languages.
Table 1 summarizes some of these functions in the programming environments we will be discussing next week.
Table 1. Main string functions
|
Spreadsheet (Excel, Calc) |
Basic (VBA, Libre Basic) |
Javascript |
|
SEARCH, FIND |
InStr |
search, indexOf |
|
MID |
Mid |
substr, substring |
|
SUBSTITUTE |
Replace |
replace |
|
TRIM |
Trim |
trim |
|
CONCATENATE |
& (operator), |
concat |